引言
- git是常用的版本管理工具
- 本文总结了git最常用的命令,应当熟记于心
- 使用git应当尽量使用命令行,这样可以帮助熟悉git的流程
配置和状态:
git status git现在状态
git init 初始化git,生成 .git 文件;
常用动作:
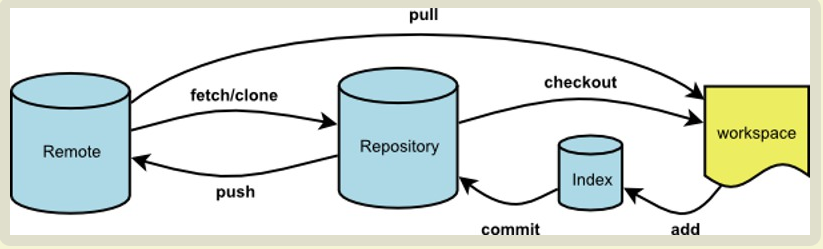
git clone (url) 将工程的master分支clone下来;
git clone (url) (空格) (目录) 仅仅将repository某个目录clone到本地;
git clone (url) (空格) /(目录) 将git这个目录下的所有文件下载到本地这个目录下;
git clone -b branchName (url) 将一个分支clone到本地;
git checkout -b csy_ui origin/csy_ui_m clone另一个分支到本地的新建分支中;
git checkout branchName 切换到某个分支,在checkout前需保证当前分支已经commit,否则会报错;
git merge (被合并分支名称) 将被合并分支合并到当前分支,执行此命令后,没有冲突的都已经merge到当前分支,有冲突的会提示,用编辑器解决完冲突后,直接add以及commit即可完成整个merge过程,不用重新merge;
git branch test 新建名为test的分支;
git checkout -b test 新建名为test的分支,并checkout到该分支;
git add . add改动到暂存区域;
git commit -a -m “….” commit改动到repository;
git push origin master push到名字为origin的远端的master分支中;
git diff 对比当前分支在当前状态下和刚刚写换到这个分支的时候有什么不同,列出改动的文件和具体改动哪些内容;
git mv old_name new_name 重命名文件
历史和记录:
git log/git log –graph 查看git历史动作
history 查看git命令历史记录