引言
- HDFS是Hadoop中的重要组件,是一种重要而文件存储机制。
- HDFS可以同时保证文件读写的效率和安全性,不怕宕机和断电。
- HDFS内部的机制相当复杂,本文会详细讲解这些机制的作用。
HDFS特点
- 流量大,流速并不快;
- 适合读写大块的文件,不适合读写大量小文件;
HDFS的组件构成
- client:如果用PC连接集群,则PC就是client,用户直接操纵client;
- namenode:HDFS管理者,保存各个文件块(默认64MB)的位置信息,保存各个datanode的状态信息,保存机架感知的信息,和datanode心跳通信;
- secondnamenode:namenode的备份;
- datanode:存储具体的文件块,每个文件块要在不同的机器上一共存储三份,保证文件的安全性;
HDFS读文件的流程
- client要读文件;
- client问namenode这个文件的几个块都放在那个datanode上面(一个文件块备有三份分别存在不同的datanode上面),优先选择离client近的数据;
- client获知datanode信息后,去相应的机器上读取文件块;
- client依次读取这个文件的所有文件块,组成完整的文件;
- 中间如果读取某个块出错,会从这个块的备份块所在datanode继续读取;
HDFS写文件流程
- client要写文件;
- client问namenode这个文件的几个块都要写在哪个datanode上面(HDFS的备份机制要求同一个文件块要写在三个datanode上面三份,其中两个datanode处于同一机架,另一个和他们不处于同一机架);
- client获知datanode信息后,去相应的机器上写文件块(client先把数据全部写在datanode1上面,datanode1将数据某一块写在datanode2,datanode2将数据某一块写在datanode3,以此类推,最后这个大文件的每一块都在相应的机器上);
- 这样做(而不是namenode同时向三台datanode写文件)的原因:client向datanode写的网络IO有限,但是datanode之间的网络IO非常宽,有利于并行;
- 如果写入过程出错,将文件写入这个datanode的节点会通知namenode写入失败,请求namenode重新分配datanode写入;
- 三个节点全部写入完毕后,分别ACK通知namenode写入完毕;
HDFS容错机制
- 应对datanode可能坏掉:datanode和namenode间的心跳机制;
- 应对网络可能断掉:ACK握手协议等;
- 应对文件/硬盘可能坏掉:对文件块进行校验码或者纠错码验证,如MD5;
- 应对namenode坏掉:用secondnamenode定期镜像备份;
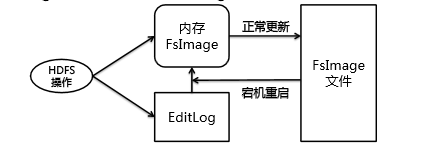
- 应对突然宕机造成的内存中的数据丢失:下面的FsImage+内存元数据+EditLog经典架构,这种架构既不只用内存(效率高但是安全性差),也不只用磁盘(效率低但是安全性好),一般是读/写数据直接面向内存,内存达到一定限值后写入磁盘,同时保证效率和安全性;
HDFS机架感知
- namenode保存机架树信息;
- 一个文件块存了三份,读文件时给client优先推荐离得近的那一份;
- 写文件时,每一个文件块都选取和client在一个机架上面的一台机器、和client相邻机架的两台机器,一共写三份;
- 这样做的好处:既保证了读写效率(一个机架上的网络IO比机架间的网络IO高),而且又在别的机架备份保证了安全性;

