引言
- ELK是重要的日志分析系统,在开源的日志分析系统中独占鳌头,最近公司业务用ELK分析告警日志,故系统研究了Elasticsearch的工作原理。
- 本文是转载的一篇文章加上我自己的整理和分析,某些内容和ELK官网重复,在此感谢作者的整理。
基本概念
- 简介:
- ElasticSearch(以下简称ES)是一个基于Lucene构建的开源(open-source),分布式(distributed),RESTful,实时(real-time)的搜索与分析(analytics)引擎。
- 它可以让你在浏览数据时具备非常快的速度和优秀的可扩展性。它用于全文索引、结构化数据索引、数据分析以及三者的结合。
- 它可以运行在你的笔记本上,或者扩展至数百台的服务器节点上来处理PB级的数据。 ES建立在Lucene的基础之上,但是Lucene仅仅是一个库,如果要发挥它的优势,你必须使用它然后再结合自己的开发来构造一个具体的应用。
- 更坏的是你必须了解Lucene才能更好的使用它,但是Lucene本身就很复杂。所以ES意在取Lucene的优点,隐蔽其复杂性来构造一个简洁易用的RESTful风格的全文搜索引擎。
- 与关系型数据库的名词对照
| SQL database | No-sql database |
|---|---|
| database | database |
| table | collection |
| row | document |
| column | field |
| primary key | primary key |
ElasticSearch专用名词解释:
- document:一行数据;
- index:一个database,是多个document的集合(和sql数据库的索引的概念不同),在kibana上显示为一组日志;
- shard:ELK的底层存储是file,shared包含一个或多个file,是数据最小存储单元,一个index被划分为若干shared分片,一个shared可以备份到其他节点上(备份的份数可以自定义);
- node:物理节点;
- cluster:集群;
面向文档(Document Oriented)
- 在应用程序中的对象(Objects),不仅仅是keys和values的罗列,更多的是,他们是由更为复杂的数据结构组成的数据构成的。迟早你会将这些对象存储到DataBases(这里指更广义的持久层)。如果你要将这些已经通过复杂的结构体组织好的对象存储到传统的ROWS-COLUMNS的关系型数据库里无疑等于压榨你的财富:因为你必须将这些已经组织好了的复杂结构扁平化来适应传统数据库的表结构(通常是一个列一个字段),然后以后每次在你要使用这个数据的时候再重组它们。
- ES面向文档,这就意味着你可以存储完整的对象或者文档。ES不仅存储它们,并且对它们的每一个文档的内容做了索引以便可以查询到它们。在ES中,你是对文档进行的建索引、查询、排序、过滤,而不是对关系型数据的一行数据。这就是ES处理数据的一个最基本的不同点,这也是ES为什么能处理全文索引的关键。
精确索引VS全文索引
- 在ES中的数据可以分为两类:精确值(exact values)以及全文(full text)。 精确值:例如日期类型date,若date其有两个值:2014-09-15与2014,那么这两个值不相等。又例如字符串类型foo与Foo不相等。 全文:通常是人类语言写的文本,例如一段tweet信息、email的内容等。
- 精确值很容易被索引:一个值要么相当要么不等。 索引全文值就需要很多功夫。例如我们不仅要想:这个文档符合我们的查询吗?还要想:这个文档有多符合我们的查询?换句话说就是:这个文档跟我们的查询关联大吗?我们很少精确的去匹配整个全文,我们最想要的是去匹配全文文本的内部信息。除此,我们还希望搜索能够理解我们的意图;
- 例如,如果你搜索UK,我们需要包含United Kingdom的文本也会被匹配。如果你搜索jump,那么包含jumped,jumps,jumping,更甚者leap的文本会被匹配。
- 为了更方便的进行全文索引,ES首先要先分析文本,然后使用分析过的文本去创建倒序索引。
倒序索引&文本分析
- ES使用倒序索引来加速全文索引。一个倒序索引由两部分组成:在文档中出现的所有不同的词;对每个词,它所出现的文档的列表。 例如:如果我们有两个文档,每一个文档有一个content字段,包含的内容如下:
1.The quick brown fox jumped over the lazy dog
2.Quick brown foxes leap over lazy dogs in summer
要创建一个倒序索引,首先要将content分割成单独的词(称为terms or tokens),创建一个所有terms的列表,然后罗列每一个term出现的文档。此过程称为tokenization。如下图:

现在,如果我们想要搜索 quick brown,我们仅仅只需要找每一个term出现的文档即可。如下图:
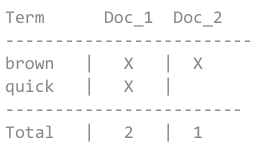
每一个文档都匹配到了,但是第一个比第二个要匹配的多。如果我们使用一个简单的相似性算法仅仅只计算匹配的数量,那么我们可以称第一个文档要比第二个匹配的好(与我们的查询更有关联)。
但是现在的倒序索引有一些问题:
Quick与quick是两个不同的term,但是搜索的用户会认为它们应该是一样的term才是合理的。
fox和foxes,dog和dogs是一样的词根,应该列为同一个term。 jumped和leap虽然词根不一样,但是意义却相同。
如果改善了上面的问题,那么倒序索引应该如下图:

但是此时如果用户搜索Quick还会失败,因为term不含精确值Quick。但是,如果我们对QueryString使用与上述改善步骤相同的策略,那么用户搜索的Quick将会被转换为quick,此过程称为normalization。那么将会成功匹配。 对content的处理tokenization和normalization称为analysis过程。ES有很多种内置的analyzer处理这些。
Elasticsearch设计原理
一个空的集群

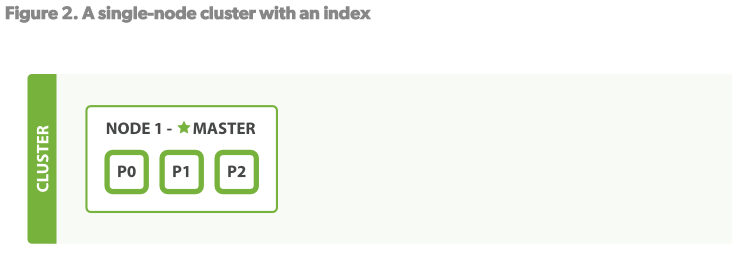
- 如果我们启动了一个节点,没有索引没有数据,那么看起来就像上图一样。 一个节点Node运行着ES的实例,一个集群由一个或多个使用着同样名字(cluster.name)的节点组成,分享数据和负载。 当Node从集群中添加或删除时,集群会重组自己,使数据平摊的更均匀。
- 集群中需要有一台master节点。master的作用是掌管集群的管理工作: 例如创建和删除索引。 从集群中添加或删除一台节点。 master节点无需掌管文档级的变更和索引。这也意味着在只有一台master的情况下,随着负载的增加master不会成为瓶颈。 所有的节点都可能变成master。
- 作为user,我们可以与任何一台节点通信,包括master。每一台节点都知道每一个文档的位置并且可以将user的请求路由到文档所在的节点,并且这台节点负责接收它路由到的node or nodes的响应,并且将数据组织起来返回给用户。这些对用户都是透明的。
创建一个索引—index,shard,cluster
- 将数据添加到ES的前提是,我们需要一个索引(名词):index——一个存储与这个索引相对应数据的地方。实际上,index仅仅只是一个命名空间来指向一个或多个实际的物理分片(shard)。
- 一个分片(shard)是一个比较低层的工作单元来处理这个索引(index)的所有数据的一个切片(slice)。一个shard实际上是一个Lucene实例,在它的能力范围内拥有完整的搜索功能(在处理它自己拥有的数据时有所有的功能)。我们所有文档的索引indexed(动词)和存储工作都是在shard上,但这是透明的,我们不需要直接和shard通信,而是和我们创建的index(名词)通信。
- shards是ES将数据分布式在你的集群的关键。想象下shards是数据的容器,文档存储在shards里,而shards被分配在集群的每一个节点Node里。当你的集群规模增长和降低时,ES会自动的在Nodes间迁移shards以保持集群的负载均衡。
- shard的分类与作用:
- shard可分为primary shard和replica shard。
- 在一个index里的每一个文档都属于一个单独的primary shard,所以primary shard的数量决定了你最大能存储的数据量(对应于一个index)。
- 注意:shard是归属与index的,而不是cluster的。
- replica shard是primary shard的拷贝。replica有两个作用:
- 冗余容灾
- 提供读请求服务,例如搜索或读取文档primary shard的数量在索引创建时确定后不能修改,replica可以在任何时候修改。 例: 见Figure2,在2.1的集群上创建一个index,拥有3个primary shards以及1个replica shards。
由于只有一台Node,而Primary shard的Replicas与其在同一台节点上毫无意义,所以集群没有初始化replicas,这时添加另外一台Node。见Figure3,每一个primary shard初始化了一个replica。

水平扩容
当我们继续添加一台节点时,Node1和Node2中的各取一个shard移动到了Node3.见Figure4
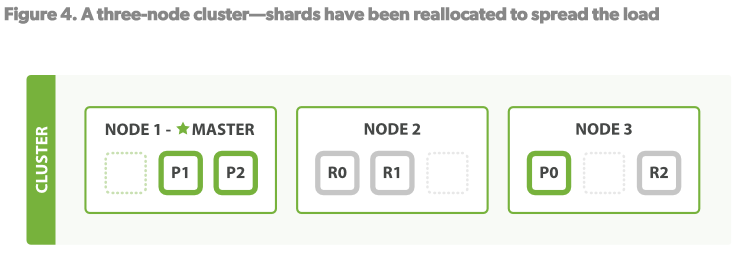
这样,我们每一台Node上只有两个shard。这就意味着每一台Node的硬件资源(CPU,RAM,I/O)将会被更少的shards共享,提高了每一个shard的性能。在这个案例中,6个shards最多可使用6台Node,这样每个shard就可以使用100%的node硬件资源。
现在我们修改replica的数量到2,如Figure5

这样我们就有了一个3primary shards,6replica shards的Cluster。我们可将Node提高到9台。水平扩容了集群性能。
容灾
ES可以容下当节点宕机情况下的异常。例如现在我们杀掉Node1节点。见Figure6
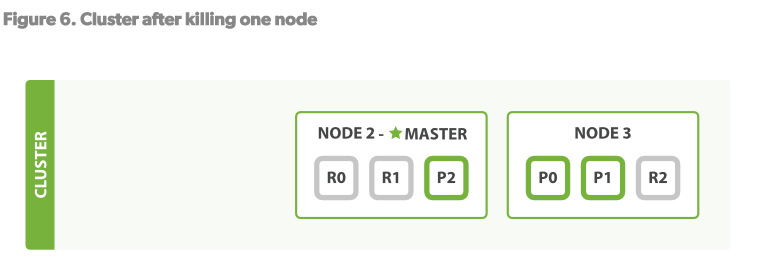
我们杀掉的是master节点。一个Cluster必须要有master以保证集群的功能正常。所以集群要做的第一件事是选择一个新的master:Node2. 当我们杀掉1节点时,Primary shards 1和2丢失了。如果丢失了primary shard,index(名词)将不能正常的工作。此时P1和P2的拷贝存在Node2和Node3上。所以此时新升级的master(Node2)将做的第一件事就是将NODE2和NODE3上的replica shard1和replica shard2升级为primary shard。此时如果我们杀掉NODE2,整个集群的容灾过程同理,还是可以正常运行。
这时,如果我们重启了NODE1,cluster将会重新分配缺少的两个replica shards(现在每个primary shard只有2个replicas,配置是3个,缺少2个)。如果NODE1的数据是旧的,那么它将会继续利用它们,NODE1只会从现在的Primary Shards拷贝这期间更改的数据。
分布式文档存储
Shards文档路由
当你对一个文档建立索引时,它仅存储在一个primary shard上。ES是怎么知道一个文档应该属于哪个shard?当你创建一个新的文档时,ES是怎么知道应该把它存储至shard1还是shard2? 这个过程不能随机无规律的,因为以后我们还要将它取出来。它的路由算法是:
shard = hash(routing) % numberofprimary_shards
routing的值可以是文档的id,也可以是用户自己设置的一个值。hash将会根据routing算出一个数值然后%primaryshards的数量。这也是为什么primary_shards在index创建时就不能修改的原因。
问题:当看到这里时,产生了一个问题:ES为什么要这样设计路由算法,这样就强制使primaryshards不可变,不利于以后index的扩容,除非事前就要对数据规模有所评估来设计可扩展的index。为什么不能使用一致性hash解决primaryshards改变时的情况呢?
Primary/Replica Shards的交互
假如我们有Figure8的集群。我们可以向这个集群的任何一台NODE发送请求,每一个NODE都有能力处理请求。每一个NODE都知道每一个文档所在的位置所以可以直接将请求路由过去。下面的例子,我们将所有的请求都发送到NODE1。

注:最好的实践方式是轮询所有的NODE来发送请求,以达到请求负载均衡。
写操作
创建、索引、删除文档都是写操作,这些操作必须在primary shard完全成功后才能拷贝至其对应的replicas上。见Figure9。
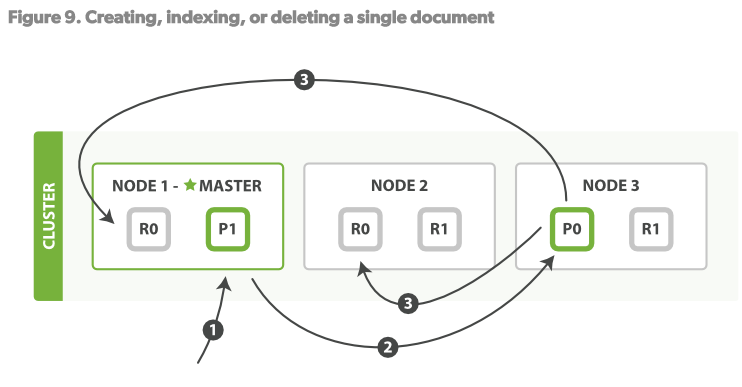
1.客户端向Node1发送写操作的请求。
2.Node1使用文档的_id来决定这个文档属于shard0,然后将请求路由至NODE3,P0所在的位置。
3.Node3在P0上执行了请求。如果请求成功,则将请求并行的路由至NODE1 NODE2的R0上。当所有的replicas报告成功后,NODE3向请求的node(NODE1)发送成功报告,NODE1再报告至Client。
当客户端收到执行成功后,操作已经在Primary shard和所有的replica shards上执行成功了。
读操作
一个文档可以在primary shard和所有的replica shard上读取。见Figure10
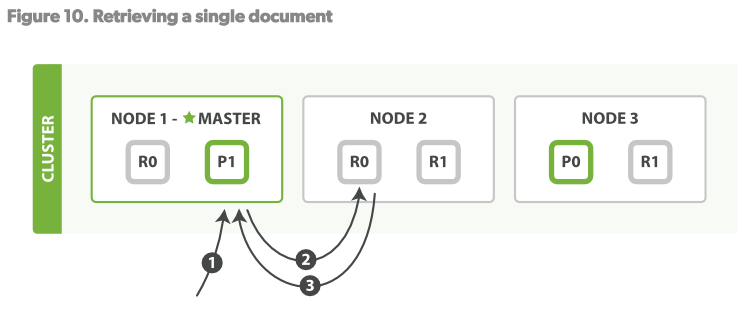
1.客户端发送Get请求到NODE1。
2.NODE1使用文档的_id决定文档属于shard 0.shard 0的所有拷贝存在于所有3个节点上。这次,它将请求路由至NODE2。
3.NODE2将文档返回给NODE1,NODE1将文档返回给客户端。 对于读请求,请求节点(NODE1)将在每次请求到来时都选择一个不同的replica。
shard来达到负载均衡。使用轮询策略轮询所有的replica shards。
更新操作
更新操作,结合了以上的两个操作:读、写。见Figure11
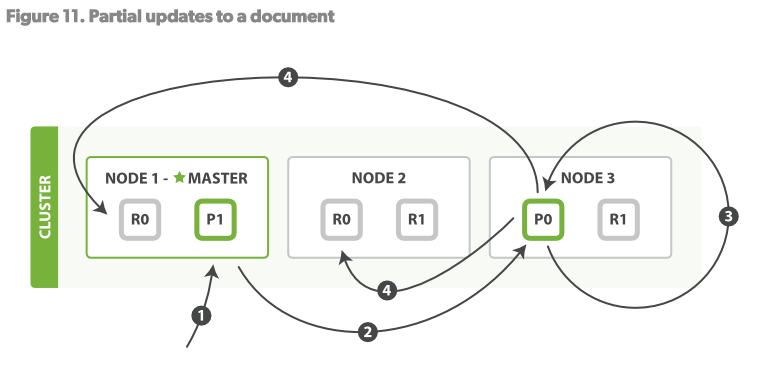
1.客户端发送更新操作请求至NODE1
2.NODE1将请求路由至NODE3,Primary shard所在的位置
3.NODE3从P0读取文档,改变source字段的JSON内容,然后试图重新对修改后的数据在P0做索引。如果此时这个文档已经被其他的进程修改了,那么它将重新执行3步骤,这个过程如果超过了retryon_conflict设置的次数,就放弃。
4.如果NODE3成功更新了文档,它将并行的将新版本的文档同步到NODE1和NODE2的replica shards重新建立索引。一旦所有的replica
shards报告成功,NODE3向被请求的节点(NODE1)返回成功,然后NODE1向客户端返回成功。
Shard以及数据读写方式的设计
不变性
- 写到磁盘的倒序索引是不变的:自从写到磁盘就再也不变。这会有很多好处:
- 不需要添加锁。如果你从来不用更新索引,那么你就不用担心多个进程在同一时间改变索引。
- 一旦索引被内核的文件系统做了Cache,它就会待在那因为它不会改变。只要内核有足够的缓冲空间,绝大多数的读操作会直接从内存而不需要经过磁盘。这大大提升了性能。
- 其他的缓存(例如fiter cache)在索引的生命周期内保持有效,它们不需要每次数据修改时重构,因为数据不变。
- 写一个单一的大的倒序索引可以让数据压缩,减少了磁盘I/O的消耗以及缓存索引所需的RAM。
- 当然,索引的不变性也有缺点。如果你想让新修改过的文档可以被搜索到,你必须重新构建整个索引。这在一个index可以容纳的数据量和一个索引可以更新的频率上都是一个限制。
动态更新索引
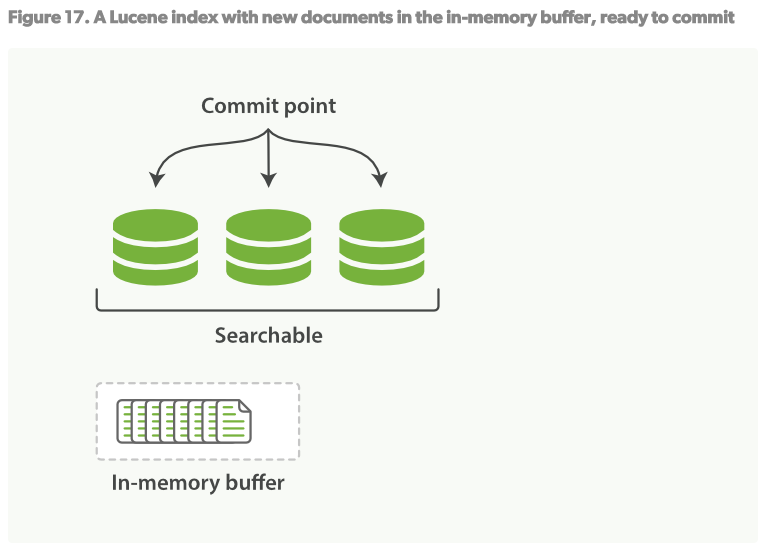
如何在不丢失不变形的好处下让倒序索引可以更改?答案是:使用不只一个的索引。 新添额外的索引来反映新的更改来替代重写所有倒序索引的方案。 Lucene引进了per-segment搜索的概念。一个segment是一个完整的倒序索引的子集,所以现在index在Lucene中的含义就是一个segments的集合,每个segment都包含一些提交点(commit point)。见Figure16。新的文档建立时首先在内存建立索引buffer,见Figure17。然后再被写入到磁盘的segment,见Figure18。
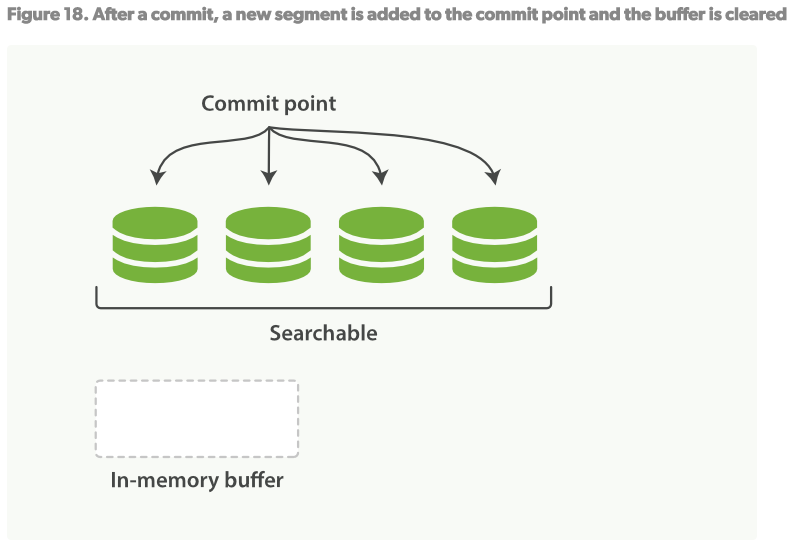
- 一个per-segment的工作流程如下:
- 新的文档在内存中组织,见Figure17。
- 每隔一段时间,buffer将会被提交:一个新的segment(一个额外的新的倒序索引)将被写到磁盘 一个新的提交点(commit point)被写入磁盘,将包含新的segment的名称。 磁盘fsync,所有在内核文件系统中的数据等待被写入到磁盘,来保障它们被物理写入。
- 新的segment被打开,使它包含的文档可以被索引。
- 内存中的buffer将被清理,准备接收新的文档。
- 当一个新的请求来时,会遍历所有的segments。词条分析程序会聚合所有的segments来保障每个文档和词条相关性的准确。通过这种方式,新的文档轻量的可以被添加到对应的索引中。
删除和更新
- segments是不变的,所以文档不能从旧的segments中删除,也不能在旧的segments中更新来映射一个新的文档版本。取之的是,每一个提交点都会包含一个.del文件,列举了哪一个segmen的哪一个文档已经被删除了。 当一个文档被”删除”了,它仅仅是在.del文件里被标记了一下。被”删除”的文档依旧可以被索引到,但是它将会在最终结果返回时被移除掉。
- 文档的更新同理:当文档更新时,旧版本的文档将会被标记为删除,新版本的文档在新的segment中建立索引。也许新旧版本的文档都会本检索到,但是旧版本的文档会在最终结果返回时被移除。
实时索引
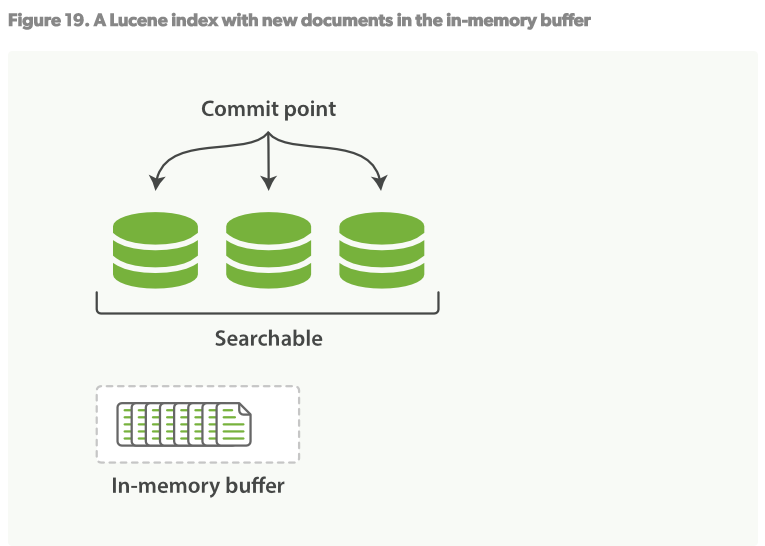
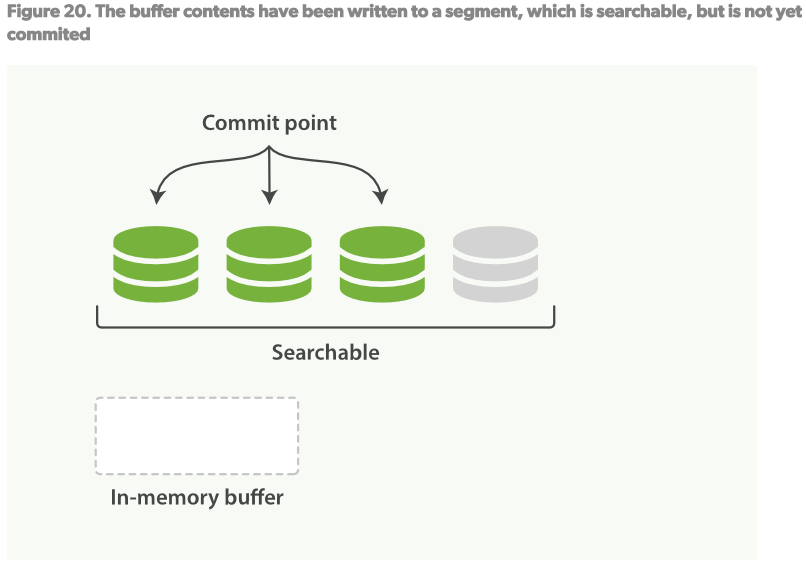
- 在上述的per-segment搜索的机制下,新的文档会在分钟级内被索引,但是还不够快。 瓶颈在磁盘。将新的segment提交到磁盘需要fsync来保障物理写入。但是fsync是很耗时的。它不能在每次文档更新时就被调用,否则性能会很低。
- 现在需要一种轻便的方式能使新的文档可以被索引,这就意味着不能使用fsync来保障。 在ES和物理磁盘之间是内核的文件系统缓存。之前的描述中,Figure19,Figure20,在内存中索引的文档会被写入到一个新的segment。但是现在我们将segment首先写入到内核的文件系统缓存,这个过程很轻量,然后再flush到磁盘,这个过程很耗时。但是一旦一个segment文件在内核的缓存中,它可以被打开被读取。
更新持久化
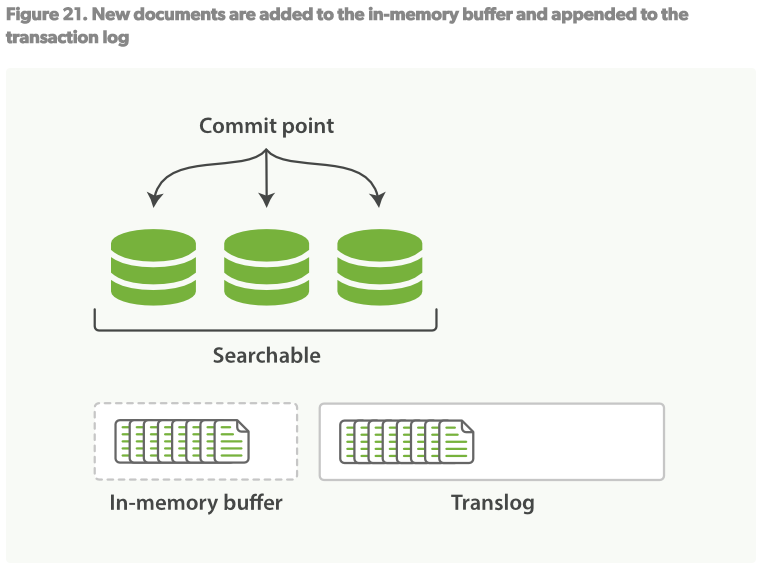
不使用fsync将数据flush到磁盘,我们不能保障在断电后或者进程死掉后数据不丢失。ES是可靠的,它可以保障数据被持久化到磁盘。 在2.6.2中,一个完全的提交会将segments写入到磁盘,并且写一个提交点,列出所有已知的segments。当ES启动或者重新打开一个index时,它会利用这个提交点来决定哪些segments属于当前的shard。 如果在提交点时,文档被修改会怎么样?不希望丢失这些修改:
- 当一个文档被索引时,它会被添加到in-memory buffer,并且添加到Translog日志中,见Figure21.
- refresh操作会让shard处于Figure22的状态:每秒中,shard都会被refreshed,在in-memory buffer中的文档会被写入到一个新的segment,但没有fsync,in-memory buffer被清空。
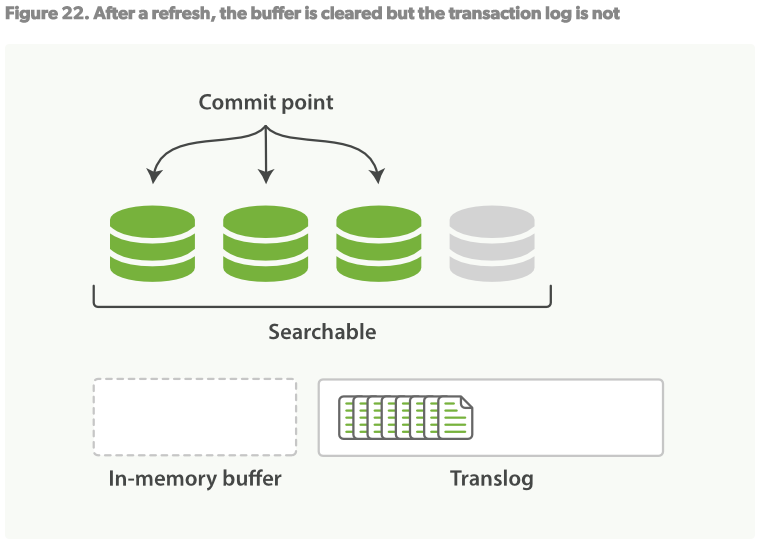
- 这个过程将会持续进行:新的文档将被添加到in-memory buffer和translog日志中,见Figure23
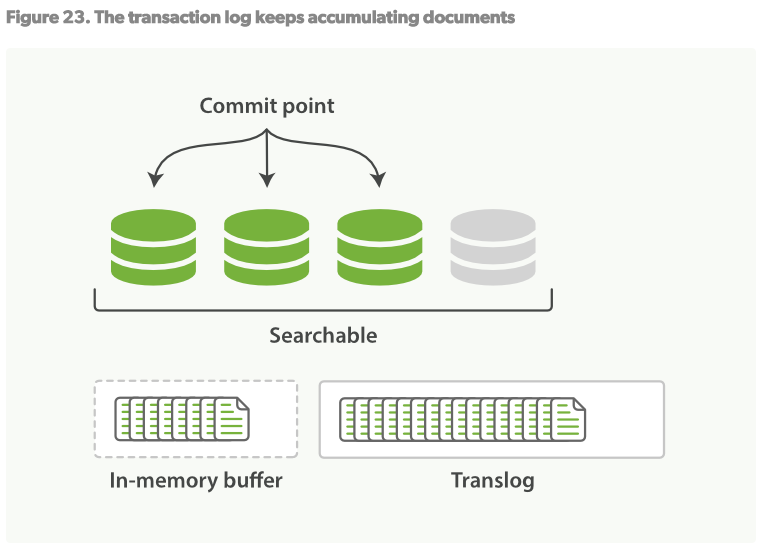
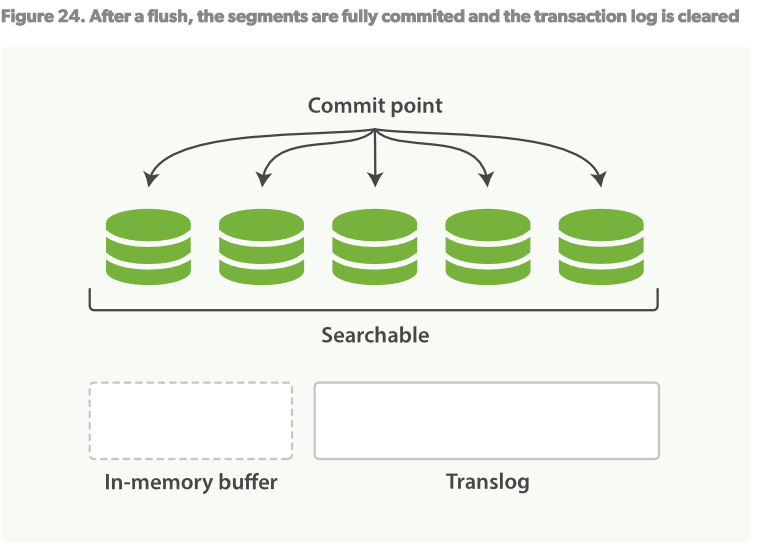
- 一段时间后,当translog变得非常大时,索引将会被flush,新的translog将会建立,一个完全的提交进行完毕。见Figure24
- 在in-memory中的所有文档将被写入到新的segment.
- 内核文件系统会被fsync到磁盘。
- 旧的translog日志被删除
translog日志提供了一个所有还未被flush到磁盘的操作的持久化记录。当ES启动的时候,它会使用最新的commit point从磁盘恢复所有已有的segments,然后将重现所有在translog里面的操作来添加更新,这些更新发生在最新的一次commit的记录之后还未被fsync。
translog日志也可以用来提供实时的CRUD。当你试图通过文档ID来读取、更新、删除一个文档时,它会首先检查translog日志看看有没有最新的更新,然后再从响应的segment中获得文档。这意味着它每次都会对最新版本的文档做操作,并且是实时的。
Segment合并
- 通过每隔一秒的自动刷新机制会创建一个新的segment,用不了多久就会有很多的segment。segment会消耗系统的文件句柄,内存,CPU时钟。最重要的是,每一次请求都会依次检查所有的segment。segment越多,检索就会越慢。
- ES通过在后台merge这些segment的方式解决这个问题。小的segment merge到大的,大的merge到更大的。。。
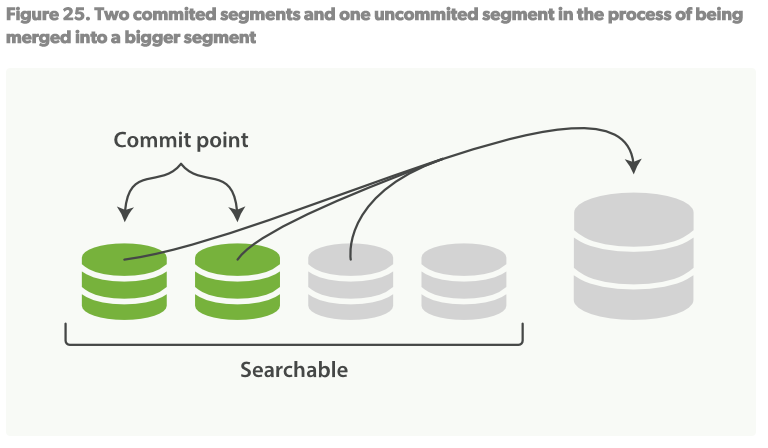
- 这个过程也是那些被”删除”的文档真正被清除出文件系统的过程,因为被标记为删除的文档不会被拷贝到大的segment中。合并过程如Figure25:
- 当在建立索引过程中,refresh进程会创建新的segments然后打开他们以供索引。
- merge进程会选择一些小的segments然后merge到一个大的segment中。这个过程不会打断检索和创建索引。
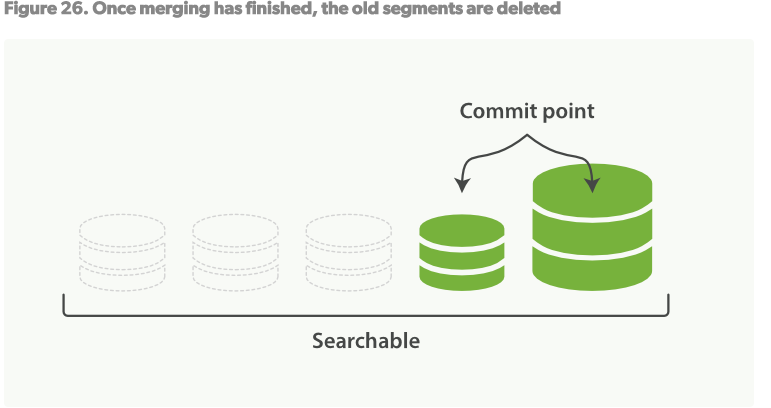
- Figure26,一旦merge完成,旧的segments将被删除:新的segment被flush到磁盘,一个新的提交点被写入,包括新的segment,排除旧的小的segments,新的segment打开以供索引旧的segments被删除。
merge大的segments会消耗大量的I/O和CPU,严重影响索引性能。默认,ES会节制merge过程来给留下足够多的系统资源。

