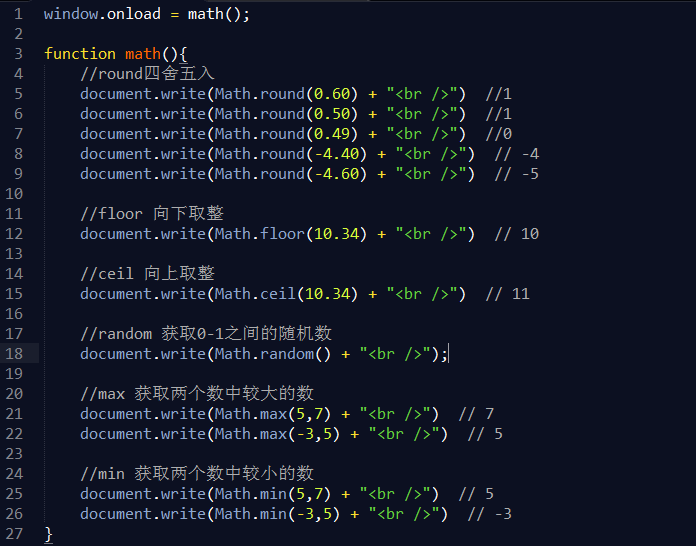
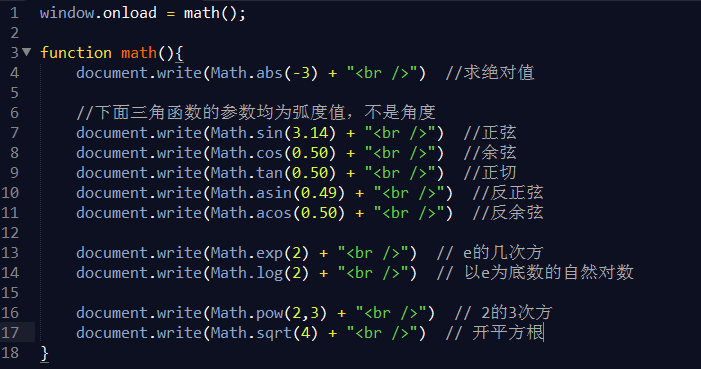
引言
- Java中,HashMap是重要的数据结构;
- HashMap用散列表实现,具体来说:
- HashMap底层维护一个数组充当哈希表;
- 当向HashMap中put一对键值时,它会根据key的hashCode值计算出一个位置,该位置就是此对象准备往数组中存放的位置,然后将key、value、next等值存放在Bucket中,作为Map.Entry;
- 如果有哈希值的冲突,即两组数据要放在数组的同一个位置(bucket)中,则用链表实现;
- 当从HashMap中get一个键值对时,HashMap会使用键对象的hashcode找到bucket位置,然后获取值对象;
- 如果数组的同一个位置对应多个键值对,将会遍历LinkedList,并调用keys.equals()方法去找到LinkedList中正确的节点,最终找到要找的值对象;
- 本文实现了一个简单的HashMap;
HashMap具体实现
- Entry类,定义节点
1 | package MyHashMap; |
- MyHashMap类,实现HashMap大部分方法
1 | package MyHashMap; |
- TestMyHashMap测试类
1 | package MyHashMap; |