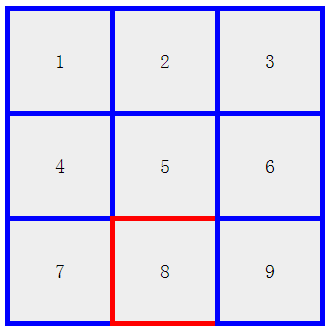
九宫格样式
- 页面显示九宫格,鼠标放在哪一个格子上,相应的格子的外边框变色;
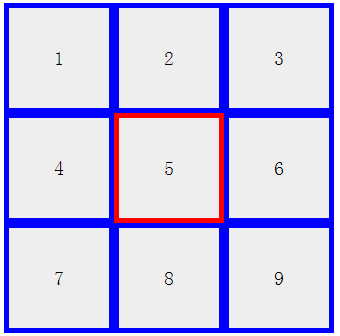
- 具体效果如下:
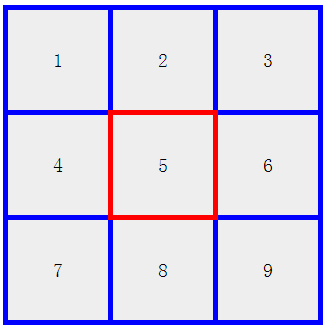
- 下面先贴出代码:
1 | <html> |
研究
- div换行问题:
<div>是块级元素,前后有换行符,如果不加任何设置,九个div将垂直排列在页面;- 解决方法是,先设置好外层、内层div的宽高,然后对内层div加入
float: left;属性,使其向左浮动,去掉div前后的换行符,由于外层div有宽度限制,内层div在达到外层div宽度后,会自动换行,实现九宫格基本样式;
- 文字的居中问题:
- 对于文字的左右居中,不需要使用position属性配合left、margin-left属性来设置,只需用特定作用于文字的属性
text-align: center;即可,这个属性不仅可以作用于文字,而且还能作用于很多块级元素,美中不足的是,如果父元素设置了text-align属性,它的所有子元素将继承这个属性的值; - 对于文字的上下居中,本来也想使用position属性配合left、margin-left属性来设置,但看到网上有牛人直接用
line-height就实现了,这个属性用于设置行间距,由于九宫格中的文字只有一行,所以将line-height设置为div的高度即可实现垂直居中效果;
- 对于文字的左右居中,不需要使用position属性配合left、margin-left属性来设置,只需用特定作用于文字的属性
- 负外边距的问题:
- 如果不对
.middle和.middle1类设置负外边距,效果是下面的样子,即处于上下中间或左右中间的格子,只对自己的外边框变化了颜色,与我们要求的效果有差距; - 通过将2、5、8格子的左右的margin设置为负值,4、5、6格子的上下的margin设置为负值,可有效避免相邻格子间的外边距叠加的问题;
- 如果不对
- 将格子的position属性设置为relative,并且将鼠标悬浮时的格子的z-index属性设置为较大的值,可保证鼠标悬浮时,当前格子总是处于最高的层叠位置,否则会出现下图的情况: